案例:用 逻辑回归 预测 信用卡欺诈
1 | import pandas as pd |
1 | data = pd.read_csv("creditcard.csv") |
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 rows × 31 columns
1数据预处理——归一化、去掉不用的列
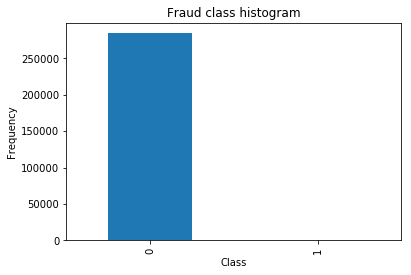
1 | count_classes = pd.value_counts(data['Class'], sort = True).sort_index() |
<matplotlib.text.Text at 0x5d32f27ef0>
1 | #用sklearn 函数来进行归一化(自带合并到原dataframe功能) |
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Class | normAmount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 0 | 0.244964 |
| 1 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 0 | -0.342475 |
| 2 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 0 | 1.160686 |
| 3 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 0 | 0.140534 |
| 4 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 0 | -0.073403 |
5 rows × 30 columns
1数据预处理——解决样本分布不均衡问题之undersample
1 | # 方式一:采用“undersample”构建模型 |
Percentage of normal transactions: 0.5
Percentage of fraud transactions: 0.5
Total number of transactions in resampled data: 984
1数据预处理——划分训练和测试集
1 | #引入数据集切分函数 |
Number transactions train dataset: 199364
Number transactions test dataset: 85443
Total number of transactions: 284807
Number transactions train dataset: 688
Number transactions test dataset: 296
Total number of transactions: 984
2 交叉验证——在训练集上做,找最好的逻辑回归正则惩罚系数C
1 | #Recall = TP/(TP+FN) 这里适用召回率来检测 |
1 | # 自己实现召回率的 K=5的交叉验证函数(注意:此处是在训练集上的交叉验证) |
1 | best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample) |
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 : recall score = 0.931506849315
Iteration 2 : recall score = 0.931506849315
Iteration 3 : recall score = 1.0
Iteration 4 : recall score = 0.972972972973
Iteration 5 : recall score = 0.969696969697
Mean recall score 0.96113672826
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 : recall score = 0.849315068493
Iteration 2 : recall score = 0.86301369863
Iteration 3 : recall score = 0.932203389831
Iteration 4 : recall score = 0.945945945946
Iteration 5 : recall score = 0.893939393939
Mean recall score 0.896883499368
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 : recall score = 0.86301369863
Iteration 2 : recall score = 0.890410958904
Iteration 3 : recall score = 0.983050847458
Iteration 4 : recall score = 0.945945945946
Iteration 5 : recall score = 0.909090909091
Mean recall score 0.918302472006
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 : recall score = 0.86301369863
Iteration 2 : recall score = 0.904109589041
Iteration 3 : recall score = 0.983050847458
Iteration 4 : recall score = 0.945945945946
Iteration 5 : recall score = 0.909090909091
Mean recall score 0.921042198033
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 : recall score = 0.876712328767
Iteration 2 : recall score = 0.890410958904
Iteration 3 : recall score = 0.983050847458
Iteration 4 : recall score = 0.945945945946
Iteration 5 : recall score = 0.909090909091
Mean recall score 0.921042198033
*********************************************************************************
Best model to choose from cross validation is with C parameter = 0.01
*********************************************************************************
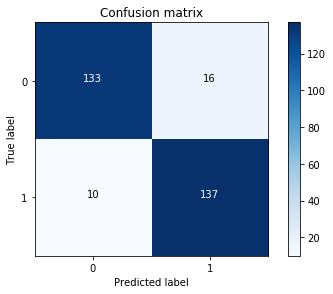
3训练 + 测试——用best_C在训练集上重新训练一遍,再在undersample测试集上预测用 混淆矩阵 计算recall值
1 | import itertools |
1 | lr = LogisticRegression(C = best_c, penalty = 'l1') |
Recall metric in the testing dataset: 0.931972789116
3训练 + 测试——用best_C在训练集上重新训练一遍,再在 完整 测试集上预测用 混淆矩阵 计算recall值
1 | lr = LogisticRegression(C = best_c, penalty = 'l1') |
Recall metric in the testing dataset: 0.918367346939
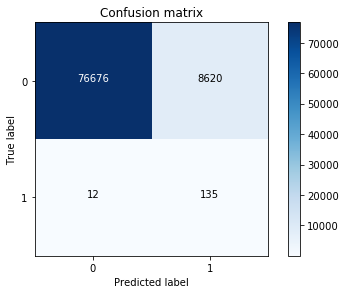
1 | 这里发现虽然recall值还可以,但是误伤了8581个(被检测成欺诈了),也就是精度accuracy有点低。 |
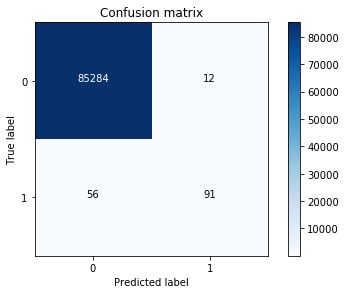
这里展示的是:不做样本平衡处理,直接把所有样本做交叉验证,发现效果很差
1 | best_c = printing_Kfold_scores(X_train,y_train) |
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 : recall score = 0.492537313433
Iteration 2 : recall score = 0.602739726027
Iteration 3 : recall score = 0.683333333333
Iteration 4 : recall score = 0.569230769231
Iteration 5 : recall score = 0.45
Mean recall score 0.559568228405
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 : recall score = 0.567164179104
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.683333333333
Iteration 4 : recall score = 0.584615384615
Iteration 5 : recall score = 0.525
Mean recall score 0.595310250644
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.716666666667
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.5625
Mean recall score 0.612645688837
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.733333333333
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.575
Mean recall score 0.61847902217
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 : recall score = 0.55223880597
Iteration 2 : recall score = 0.616438356164
Iteration 3 : recall score = 0.733333333333
Iteration 4 : recall score = 0.615384615385
Iteration 5 : recall score = 0.575
Mean recall score 0.61847902217
*********************************************************************************
Best model to choose from cross validation is with C parameter = 10.0
*********************************************************************************
1 | lr = LogisticRegression(C = best_c, penalty = 'l1') |
Recall metric in the testing dataset: 0.619047619048
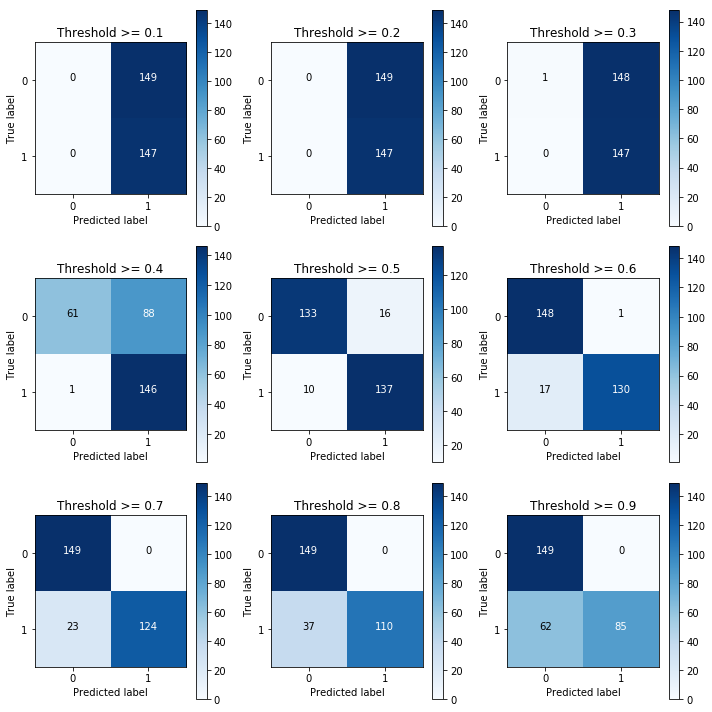
4 用predict_proba来测试 最好的逻辑回归 阈值
1 | lr = LogisticRegression(C = 0.01, penalty = 'l1') |
Recall metric in the testing dataset: 1.0
Recall metric in the testing dataset: 1.0
Recall metric in the testing dataset: 1.0
Recall metric in the testing dataset: 0.993197278912
Recall metric in the testing dataset: 0.931972789116
Recall metric in the testing dataset: 0.884353741497
Recall metric in the testing dataset: 0.843537414966
Recall metric in the testing dataset: 0.748299319728
Recall metric in the testing dataset: 0.578231292517
1数据预处理——解决样本分布不均衡问题之oversample
1 | import pandas as pd |
1 | credit_cards=pd.read_csv('creditcard.csv') |
1 | #划分数据集 |
1 | #★SMOTE算法通过给定的训练集,生成新的随机扩充训练集 |
1 | #生成前,label=0 |
227454
227454
1 | os_features = pd.DataFrame(os_features) |
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 : recall score = 0.890322580645
Iteration 2 : recall score = 0.894736842105
Iteration 3 : recall score = 0.968617904172
Iteration 4 : recall score = 0.944471922709
Iteration 5 : recall score = 0.958397907255
Mean recall score 0.931309431377
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 : recall score = 0.890322580645
Iteration 2 : recall score = 0.894736842105
Iteration 3 : recall score = 0.970255615802
Iteration 4 : recall score = 0.959991646608
Iteration 5 : recall score = 0.96051922929
Mean recall score 0.93516518289
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 : recall score = 0.890322580645
Iteration 2 : recall score = 0.894736842105
Iteration 3 : recall score = 0.970211353325
Iteration 4 : recall score = 0.960134533584
Iteration 5 : recall score = 0.960442290148
Mean recall score 0.935169519962
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 : recall score = 0.890322580645
Iteration 2 : recall score = 0.894736842105
Iteration 3 : recall score = 0.970322009516
Iteration 4 : recall score = 0.95977182049
Iteration 5 : recall score = 0.960783020631
Mean recall score 0.935187254678
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 : recall score = 0.890322580645
Iteration 2 : recall score = 0.894736842105
Iteration 3 : recall score = 0.969635941131
Iteration 4 : recall score = 0.960255437949
Iteration 5 : recall score = 0.960398324925
Mean recall score 0.935069825351
*********************************************************************************
Best model to choose from cross validation is with C parameter = 10.0
*********************************************************************************
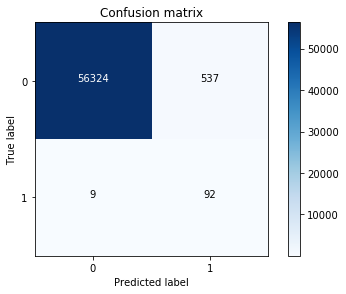
1 | lr = LogisticRegression(C = best_c, penalty = 'l1') |
Recall metric in the testing dataset: 0.910891089109
1 |
1 |
1 |